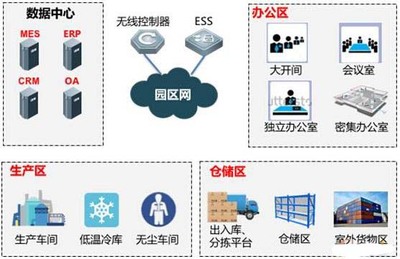
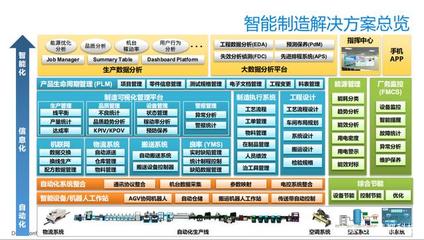
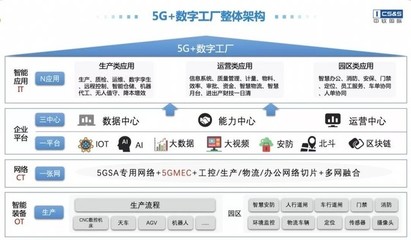
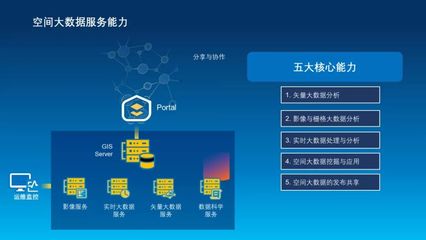
2017大數(shù)據(jù)十大趨勢 海量數(shù)據(jù)洶涌而來,Hadoop不再一家獨大

2017年,大數(shù)據(jù)領(lǐng)域進入一個更為成熟與多元化的新階段。海量數(shù)據(jù)的生成速度持續(xù)加快,數(shù)據(jù)來源日益復(fù)雜,推動著技術(shù)架構(gòu)與應(yīng)用模式的深刻變革。其中,最引人注目的趨勢是,以Hadoop為核心的生態(tài)系統(tǒng)雖然依然重要,但已不再是處理大數(shù)據(jù)的唯一選擇。數(shù)據(jù)處理范式正在從“批處理優(yōu)先”轉(zhuǎn)向“流處理優(yōu)先”,實時分析能力成為關(guān)鍵競爭力。
在此背景下,我們梳理出2017年大數(shù)據(jù)的十大核心趨勢:
- 實時流處理的崛起:Apache Kafka、Apache Flink、Apache Beam等流處理框架受到青睞,企業(yè)需要即時從數(shù)據(jù)流中獲取洞察,以支持實時決策、欺詐檢測和個性化推薦。
- Hadoop生態(tài)的演化與融合:Hadoop作為批處理的基石地位穩(wěn)固,但其生態(tài)系統(tǒng)(如Spark)在性能和易用性上不斷進化。云端托管Hadoop服務(wù)(如Amazon EMR、Azure HDInsight)降低了使用門檻,使其更易集成到混合架構(gòu)中。
- 云原生與混合架構(gòu)成為主流:大數(shù)據(jù)處理越來越多地部署在云端。云服務(wù)商提供全托管的大數(shù)據(jù)服務(wù)(如BigQuery、Redshift、Snowflake),實現(xiàn)了存儲與計算的分離,提供了彈性、可擴展且成本更優(yōu)的解決方案。混合云架構(gòu)兼顧了數(shù)據(jù)本地化與云端的靈活性。
- 人工智能與機器學(xué)習的深度集成:大數(shù)據(jù)是AI/ML的燃料。TensorFlow、PyTorch等框架與大數(shù)據(jù)平臺(如Spark MLlib)緊密結(jié)合,使得從海量數(shù)據(jù)中訓(xùn)練模型、進行預(yù)測分析變得更加順暢。
- 數(shù)據(jù)湖與數(shù)據(jù)倉庫的界限模糊:企業(yè)開始構(gòu)建“數(shù)據(jù)湖倉一體”(Lakehouse)架構(gòu),試圖融合數(shù)據(jù)湖的低成本、多格式存儲能力與數(shù)據(jù)倉庫的強大管理、高性能查詢優(yōu)勢。
- 數(shù)據(jù)治理與安全備受關(guān)注:隨著GDPR等法規(guī)出臺和內(nèi)部數(shù)據(jù)資產(chǎn)化管理需求,數(shù)據(jù)的質(zhì)量、血緣、安全與隱私保護被提升到戰(zhàn)略高度。相關(guān)工具和平臺得到快速發(fā)展。
- 邊緣計算賦能物聯(lián)網(wǎng)大數(shù)據(jù):物聯(lián)網(wǎng)設(shè)備產(chǎn)生巨量邊緣數(shù)據(jù)。為了降低延遲和帶寬成本,在數(shù)據(jù)產(chǎn)生源頭(邊緣端)進行實時過濾、預(yù)處理和分析變得至關(guān)重要。
- 自助式數(shù)據(jù)分析工具普及:Tableau、Power BI等工具讓業(yè)務(wù)人員能夠直接探索和分析數(shù)據(jù),減少對IT部門的依賴,提升了數(shù)據(jù)驅(qū)動決策的文化和效率。
- 開源持續(xù)驅(qū)動創(chuàng)新:開源社區(qū)(如Apache基金會)依然是大數(shù)據(jù)技術(shù)創(chuàng)新的核心引擎,從存儲、計算到管理,開源項目構(gòu)成了技術(shù)選型的基礎(chǔ)。
- 大數(shù)據(jù)即服務(wù)(BDaaS)走向成熟:企業(yè)更傾向于購買端到端的大數(shù)據(jù)解決方案服務(wù),而非自行搭建和維護復(fù)雜的基礎(chǔ)設(shè)施。這降低了技術(shù)復(fù)雜性,讓企業(yè)能更專注于業(yè)務(wù)價值提取。
總而言之,2017年的大數(shù)據(jù)領(lǐng)域呈現(xiàn)出“去中心化”和“服務(wù)化”的鮮明特征。技術(shù)的多元化選擇讓企業(yè)能夠根據(jù)自身業(yè)務(wù)場景(實時或批處理、云端或本地)構(gòu)建最合適的架構(gòu)。海量數(shù)據(jù)的價值挖掘,正從技術(shù)挑戰(zhàn)轉(zhuǎn)向如何更智能、更實時、更安全、更易用地服務(wù)于業(yè)務(wù)創(chuàng)新。Hadoop作為時代的開創(chuàng)者功不可沒,但大數(shù)據(jù)的世界已進入一個百花齊放、各展所長的全新格局。
如若轉(zhuǎn)載,請注明出處:http://www.hardwarexpo.com.cn/product/21.html
更新時間:2026-04-14 23:38:34